The most important design choice is that AI sits on top of explicit analytical logic instead of replacing it.
Abstract
Pythia Analytics is the result of repeatedly hitting the edge of a workflow, then replacing that edge with software.
This project did not begin as a full investment platform. It began as a constrained research problem inside a student-managed fund: analyze a broad industrial universe quickly enough to surface a real value opportunity within a short semester timeline. The first answer was a news-sentiment workflow. That was useful, but incomplete. It became a mass-DCF script, then a deeper analysis system, then a broader portfolio and thesis platform, then a macro dashboard, and finally a trading and backtesting layer.
That progression matters because it explains the product architecture. Pythia Analytics is not a single model or page. It is a cumulative attempt to turn fragmented investment research into a repeatable software system where deterministic valuation, saved reasoning, portfolio decisions, macro context, and AI-assisted synthesis can live in the same workflow.
The core technical principle is simple: language models should sit on top of explicit analytical logic, not replace it. The most important work in the app is still deterministic: Company DNA, classification, scenario-aware valuation, blended fair value, persistence, and decision tracking. AI is used to compress and operationalize that work, especially in commentary, thesis management, and sell-discipline generation.
1. Origin Problem and Why the App Kept Growing
The original use case was narrow and practical. A student-managed investment fund needed to analyze the industrial sector under real time pressure and still come away with a defendable value idea. The earliest workflow looked like what many investment teams and retail investors still do manually:
- scan large volumes of news and filings
- pull together sentiment or commentary by hand
- narrow a list of candidates
- build DCF work in separate scripts or spreadsheets
- reconstruct the reasoning later from memory, notes, and disconnected files
The first version of the app targeted that bottleneck through news sentiment analysis. That solved one problem, but it exposed a larger one. Sentiment could help triage attention, but it could not answer the valuation question by itself. The result was a second phase: a general mass-DCF script for selected names. That, in turn, exposed another gap. Once valuation existed, the next missing pieces were classification, saved research state, portfolio reuse, thesis tracking, macro context, and trade validation.
This is why the project did not expand through one dramatic pivot. It expanded through hundreds of small missing moments.
Product evolution
The app's evolution is best understood as a chain rather than a jump:
news sentimentmass DCF scriptfull analysisfull analysis / portfolio / thesis platformfull analysis / portfolio / thesis platform / Macro Dashboardfull analysis / portfolio / thesis platform / Macro Dashboard / Trading Engine
That sequence is the product thesis in compressed form. Every new layer was added because the previous layer still left part of the investing workflow fragmented.
2. Product Thesis: Valuation Cannot Exist in a Vacuum
A valuation engine should not behave like a detached calculator. It should know what kind of company it is looking at, what peers matter, and what market regime it is operating inside.
That idea drives the current shape of the app.
Pythia Analytics is built around a simple belief: valuation must be grounded in comparables, industry benchmarks, and macro context. A model that produces a number without that surrounding context is not enough. It may still be mathematically coherent, but it is not yet useful in the way investors actually make decisions.
That belief shows up across the product:
- the analysis engine does not stop at raw ratios
- Company DNA translates financial history into a business profile
- classification changes downstream assumptions and weights
- fair value is blended instead of delegated to one method
- macro context exists as its own first-class surface
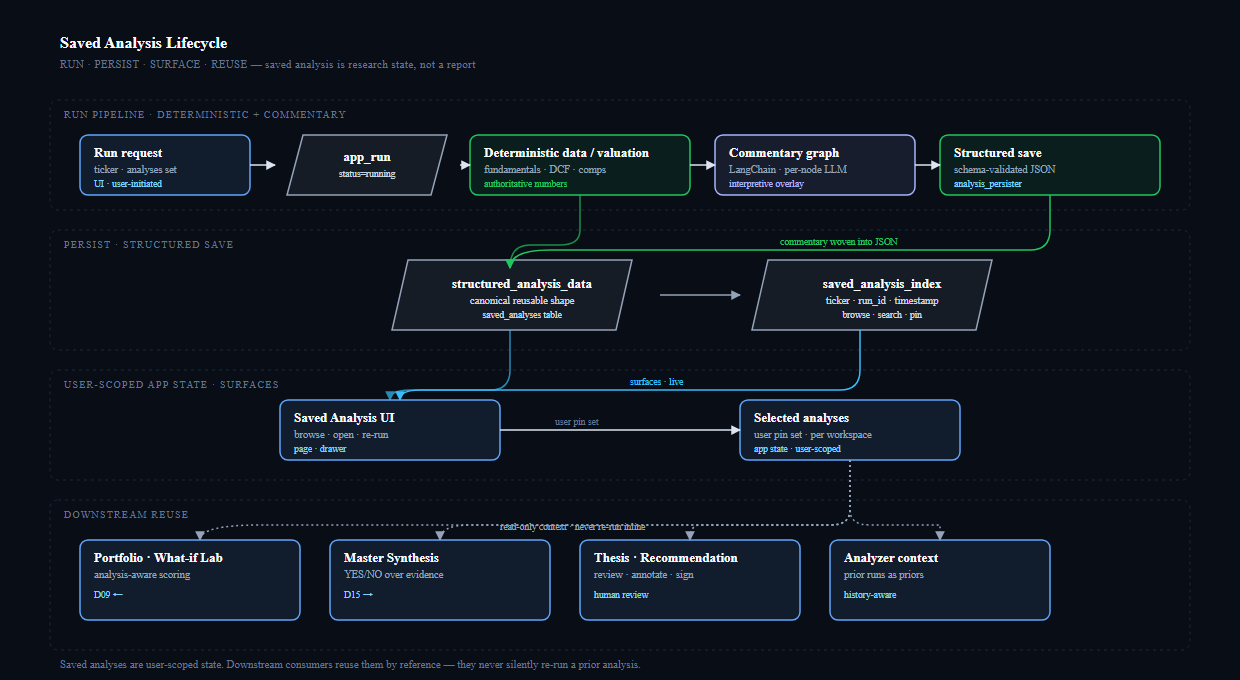
- saved analysis can later feed portfolio and thesis decisions instead of disappearing after one session
In short, the app is trying to make research stateful. The goal is not only to answer "What is this company worth?" but also "Why do I think that, what evidence supports it, and what would make me change my mind later?"
3. Architecture and Boundaries
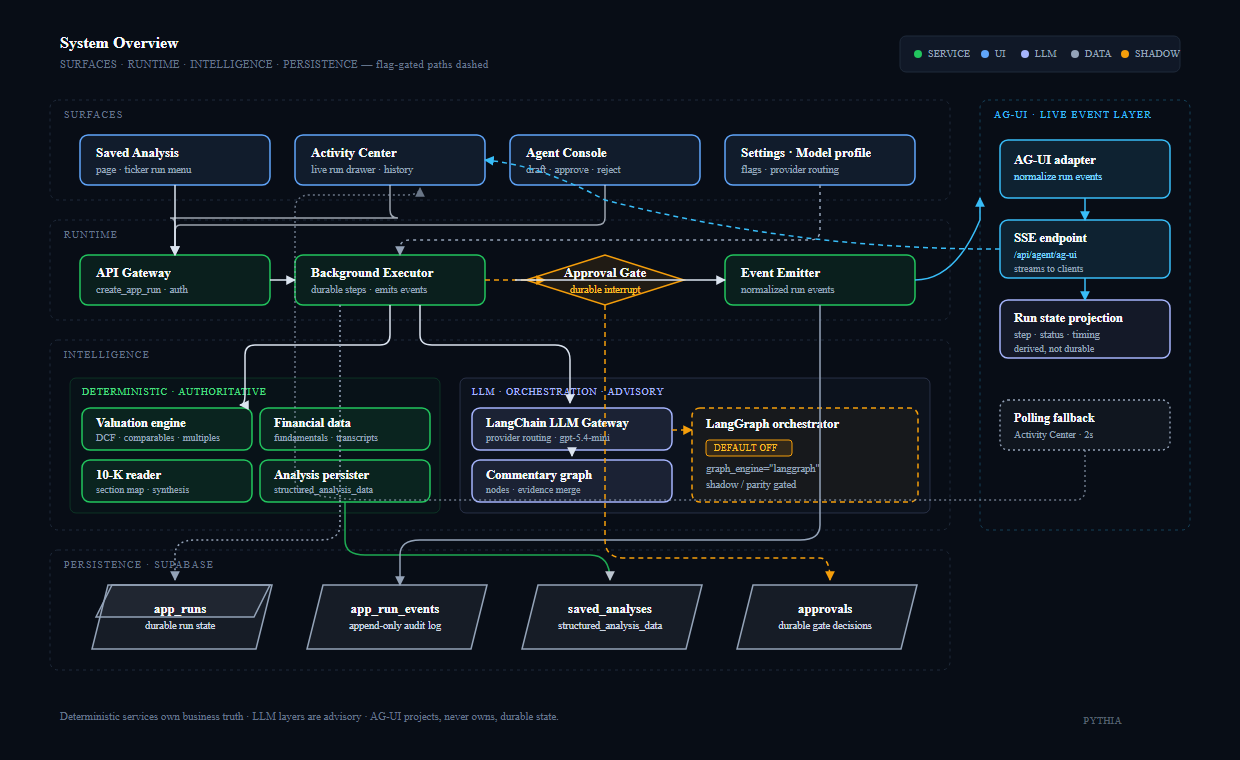
The application boots from app.py and follows a page-based Dash structure. At a high level:
pages/owns route-level layouts, UI composition, and higher-level callbacksutils/owns shared services, persistence, auth, data access, helper logic, and cross-page functionalityvaluation_models/owns side-effect-free valuation math
This separation matters because the codebase did not start as a neatly segmented system. Like most cumulative projects, it became more coherent as the boundaries became clearer. The benefit is practical:
- page concerns stay local instead of leaking everywhere
- shared logic becomes reusable across analysis, portfolio, macro, and trade workflows
- valuation code remains inspectable
- persistence and auth concerns can evolve without being mixed into every UI callback
- public-facing Pythia Blog content can exist without tangling with private product flows
The repo documentation reinforces the same architecture. The analysis docs explain the valuation and narrative layering, the whitepaper sections document system design and governance, and the database map shows a broader application surface than a simple one-page dashboard.
4. The Core Analysis Engine
The strongest technical part of the product is the Analysis page. This is where the app most clearly combines deterministic finance logic with AI-assisted interpretation without letting the second replace the first.
The internal structure is well described by the repo docs:
market and fundamentals -> current snapshot -> Company DNA -> classification -> scenarios -> valuation models -> blended outputs -> commentary and recommendation
That sequence is the center of gravity for the app.
4.1 Company DNA as a real downstream input
One of the most important design choices in the analysis engine is that Company DNA is not cosmetic labeling. It is an expansive deterministic flag layer built from growth, profitability, margins, free-cash-flow behavior, capital intensity, leverage, liquidity, payout behavior, buybacks, and stability signals.
The point of that layer is not merely to describe a company in prose. It is to create a structured profile that almost always matters downstream.
In the codebase, Company DNA feeds:
- company classification
- scenario logic
- weighting adjustments inside the valuation pipeline
- cost-of-equity and WACC-related hooks
That is the right architectural move. Raw financial history is too low-level to be the final decision layer, but generic AI text is too high-level to be trusted on its own. Company DNA sits in the middle and converts raw statements into a reusable profile that later systems can actually act on.
4.2 Why classification matters
The classification layer is one of the areas that makes the analysis engine feel productized rather than improvised. The app is not treating every company as though it should be valued the same way.
A Blue-Chip archetype is a good example. When the business profile points toward a more stable, established company, that should affect how the system thinks about durability, discounting, payout behavior, margin quality, and the relative credibility of different valuation methods. A cyclical or more fragile business should not inherit the same assumptions.
That is the value of classification. It creates a bridge between financial character and valuation mechanics.
4.3 DCF mechanics and scenario-aware assumptions
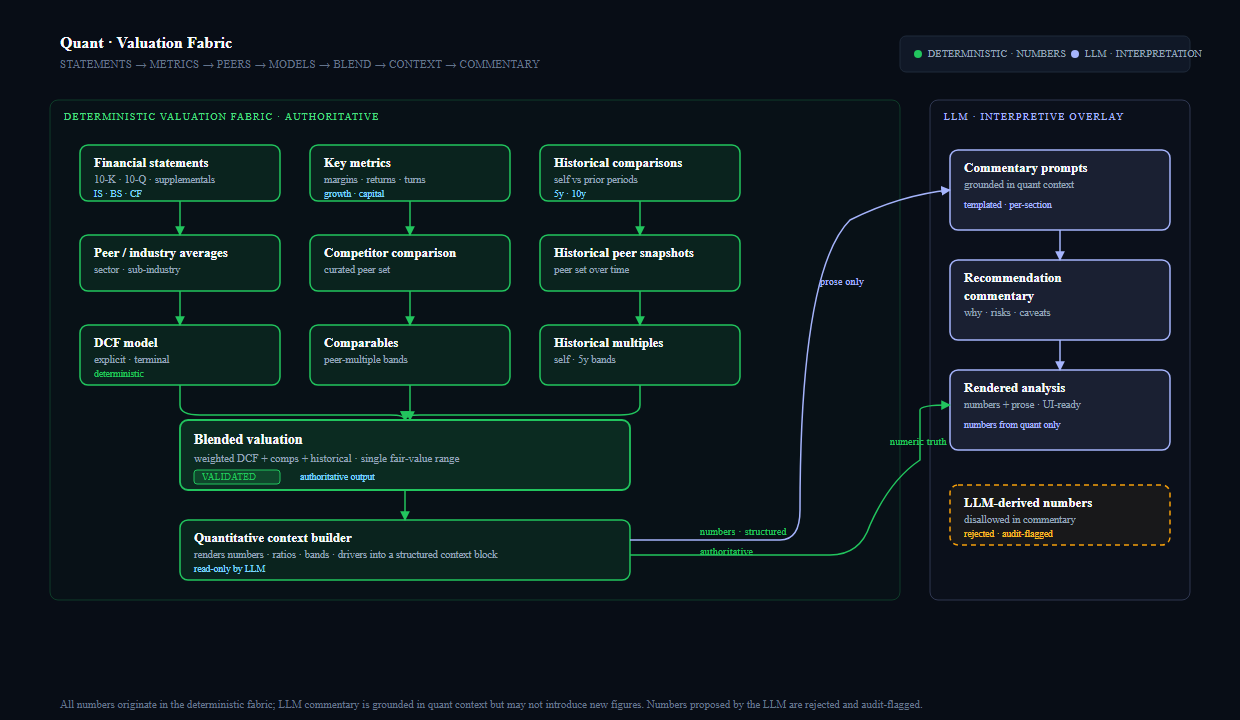
The valuation engine matters most in its DCF mechanics and in how it handles assumptions. The app does not rely on one static DCF with one permanent cost of capital. It uses explicit scenarios and DNA-aware assumptions to build pessimistic, moderate, and optimistic views.
This is important for two reasons.
First, it makes the model more honest. There is rarely one defensible future path for a business. Second, it makes the assumptions inspectable. The user can see that fair value is constructed from scenario choices, discount rates, growth expectations, and company profile, rather than being produced as a black-box output.
The deeper point is that the DCF pipeline is not isolated from the rest of the system. Company DNA and classification are designed to reach into the valuation logic itself.
4.4 Blended and weighted fair value
The fair-value layer is also stronger than a single-model approach because it explicitly treats valuation as contextual. The weighting philosophy is not "pick one favorite model and trust it." The philosophy is closer to:
- no valuation should exist in a vacuum
- comparables and industry structure matter
- macro conditions matter
- different company types deserve different mixes of methods
That is why the app blends DCF outputs with multiple-based approaches and adjusts those weights by classification and valuation group. It is a more realistic way to think about valuation. Investors do not really value companies with a single isolated formula. They triangulate.
Pythia Analytics tries to make that triangulation systematic.
5. AI Layer: Interpretation, Compression, and Decision Discipline
The AI layer is strongest when it explains and operationalizes the deterministic work that already exists.
The app uses language models where language is the bottleneck:
- summarizing annual and quarterly context
- turning transcript and filing material into readable commentary
- connecting macro context to company-specific analysis
- generating or refining stored thesis language
- deriving monitoring language such as key metrics and thesis breakers
This is a strong design choice because it keeps the trust boundary clear. The language model is not supposed to invent the numeric foundation. It is supposed to interpret it, organize it, and convert it into decision-ready language.
That principle becomes especially useful in the thesis workflow.
5.1 Thesis engine as a living decision object
The Portfolio Manager already includes a full Thesis & Rules tab rather than a placeholder concept. For each holding, the product can preserve:
- an investment thesis
- key metrics to watch
- thesis breakers
- rebalancing rules
That matters because research usually degrades after the initial write-up. The number is saved, but the reasoning is lost. Here, the saved analysis can persist as an editable decision object.
The LLM-generated language is particularly useful in the thesis-breaker layer because it turns analysis into sell discipline. One example of the style the system can express is straightforward: if a company has established a pattern of consistent EPS beats, a meaningful miss can become a thesis breaker rather than a noisy quarter. That kind of language is not replacing analysis. It is preserving accountability to the original thesis.
6. Portfolio Construction, Macro Context, and the Feedback Loop
The portfolio layer should be framed honestly. It is not claiming to invent portfolio theory. The optimizer is closer to a productized efficient-frontier workflow built around the user's selected universe, return goals, and volatility limits.
That is still meaningful work.
What matters is not whether the mathematics are novel. What matters is that the optimizer exists inside the same product as the analysis engine, saved research, and thesis layer. The user can move from single-name work to portfolio construction without abandoning context.
The Macro Dashboard extends the same logic upward. If valuation should not exist in a vacuum, then portfolio work should not exist in a vacuum either. Macro context becomes part of the same decision environment rather than a separate browser tab or spreadsheet.
This is one of the more professional qualities of the repo: it tries to keep the loop connected.
- analyze a company
- save the work
- use it inside a portfolio
- connect it to a thesis and monitoring rules
- revisit it under changing macro conditions
That loop is more important than any one page.
7. Trading Engine and Backtesting Philosophy
The trading engine is becoming more technically interesting for a different reason than the valuation engine. Here the story is less about classification and more about validation discipline.
The current strategy work is deliberately harsh on itself. The goal is not to overfit a clean backtest. The goal is to add as many bad constraints as possible and force a strategy to survive them. In practice, that means pressure from conditions such as:
- high total transaction costs
- exposure penalties
- universe constraints
That is the right instinct. A trading system becomes more credible when its assumptions get less forgiving, not more.
At this stage, only one strategy family has really emerged as established: pullback_breakout. That is not a weakness in the story. It is evidence of rigor. Most ideas fail. The one that survived mainly survived because it received the most time, refinement, and repeated validation effort.
For a technical reviewer, this says something important about the project. The build is not just adding features. It is also learning how to reject weak ones.
8. Data, Persistence, and Operational Maturity
The persistence layer is a major reason the app feels like software instead of a collection of scripts. The database map and repo utilities show a system that already thinks in terms of:
- saved analytical state
- portfolio records
- transactions
- theses and rules
- user settings
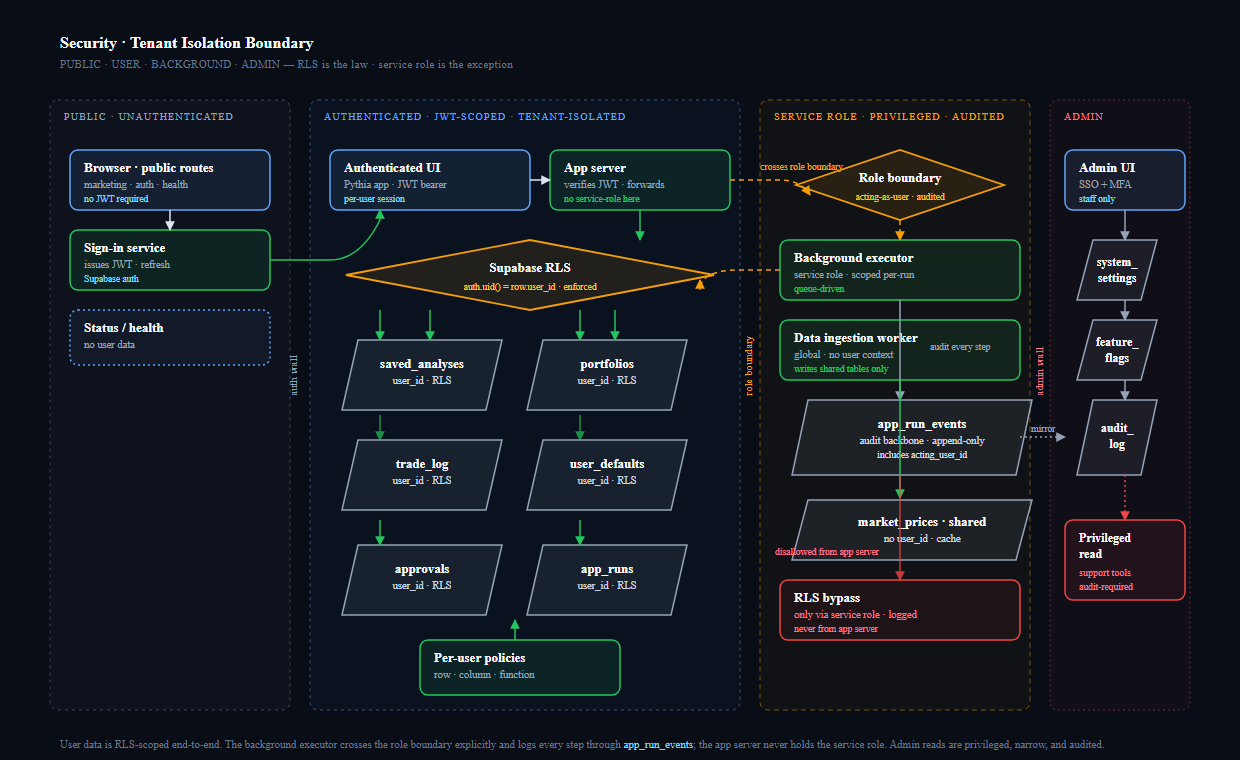
- auth-aware ownership boundaries
That is essential for an investing product. Analysis only becomes durable when it can be saved, revisited, compared against later outcomes, and tied back to a user or portfolio context.
The repo also shows growing attention to operational concerns:
- Supabase auth and row-level boundaries
- secret management and environment-based configuration
- migration and refresh scripts
- separate public-facing content routes
Those details matter because they reveal intent. The project is being treated as an application that could support real users, not just as an experimental notebook environment.
9. What This Project Demonstrates
Pythia Analytics is not impressive because every subsystem is finished. It is impressive because the subsystems are increasingly connected, explicit, and grounded in real workflow pressure.
The strongest signals in the codebase are:
- a real origin problem instead of a vague app idea
- cumulative product growth driven by repeated workflow gaps
- a deterministic analysis core with genuine downstream structure
- valuation logic that is contextual rather than isolated
- AI used as an interpretation and operationalization layer instead of a replacement for math
- saved research, thesis, and portfolio workflows that preserve reasoning over time
- a trading engine whose validation philosophy values failure filtering over easy wins
For a recruiter, builder, or technical reviewer, the conclusion I would draw is straightforward:
this is the work of someone who likes solving systems problems, especially where finance, software design, and decision workflows intersect.
That is the core story of the app.